
Boundary Equilibrium Generative Adversarial Networks(BEGAN) [arXiv:1703.10717]
第二話
挨拶
G : 今週のヤンジャンはGWのため、お休みでした。どうも泣きそうなguguchiです。
M : guguchiによると今週ヤンジャン休みみたいです。悔しいです。masoです。
G : 今週は1ヶ月くらい前にバズっていたBEGAN:Boundary Equilibrium Generative Adversarial Networks(以下、BEGAN)を読んでいきたいと思います。
会話
G : まず概要について説明します。BEGANは、discriminatorにauto-encoderを使って、生成モデルの再構成誤差の分布と真の分布の再構成誤差の分布のWasserstein距離を小さくしようという論文です。特徴は、従来のmin-maxの定式化ではなく、2つの目的関数を最小化するという定式化になっている所ですね。論文中のリザルトの生成された顔画像は、エグいぐらいすごいリアリティーがありますね。
M : 俺ちょっとこの論文意味分かんないんだけど。。。
G : masoさん、僕もめっちゃ意味わかんないとこありました。
M : やっぱり?とりあえず、論文中の式見ていきましょう!
G : そうですね!まずは、discriminatorがでパラメトライズされたauto-encoderになっていて、再構成誤差は
で計算されます。
M : Gをgeneratorとすると、この手法のdiscriminatorの目的は、は0に近づける。一方でとのWasserstein距離を遠ざけることだね。
G : そうです。ここで一つの仮定が入ります。それは、真の分布・生成モデルの再構成誤差の分布がそれぞれ
になるという仮定です。
M : 論文中では、”We found experimentally, for the datasets we tried, the loss distribution is, in fact, approximately normal.”って言ってますね。この仮定を使うと、ガウシアンのWasserstein距離が解析的に計算できるという性質が使えます。すると
が導けます。さらに次元が1次元の場合は、
で計算できます。
G : そうですね。ここでもう1つ僕的によくわかんない仮定が入ります。が定数になるという仮定です。masoさんこれって大丈夫なんですか?
M : 平均が小さかい時はバリアンスも小さい、平均が大きい時はバリアンスも大きいっていうのはそんなにおかしくないんじゃない?
G : まぁ、そうか。。。
M : 本当にやばいのは論文の3.2からだよ。
G : そうなんですね。3.2では、まず再構成誤差の分布のWasserstein距離をどうやってでかくするかについて述べています。再構成誤差のWasserstein距離を大きくする方法は
(a)と(b)の2つがあると言っています。ただ真の分布の再構成誤差は0になって欲しい。つまり、(b)の場合を選択すると言ってます。この場合、2つの目的関数をminimizationするという定式化ができるらしく、
になると言っています。
M : 今まではDでW距離を大きくして、GでW距離を小さくしてたけど、これって逆じゃない?ちょっと可視化してしてみよう!
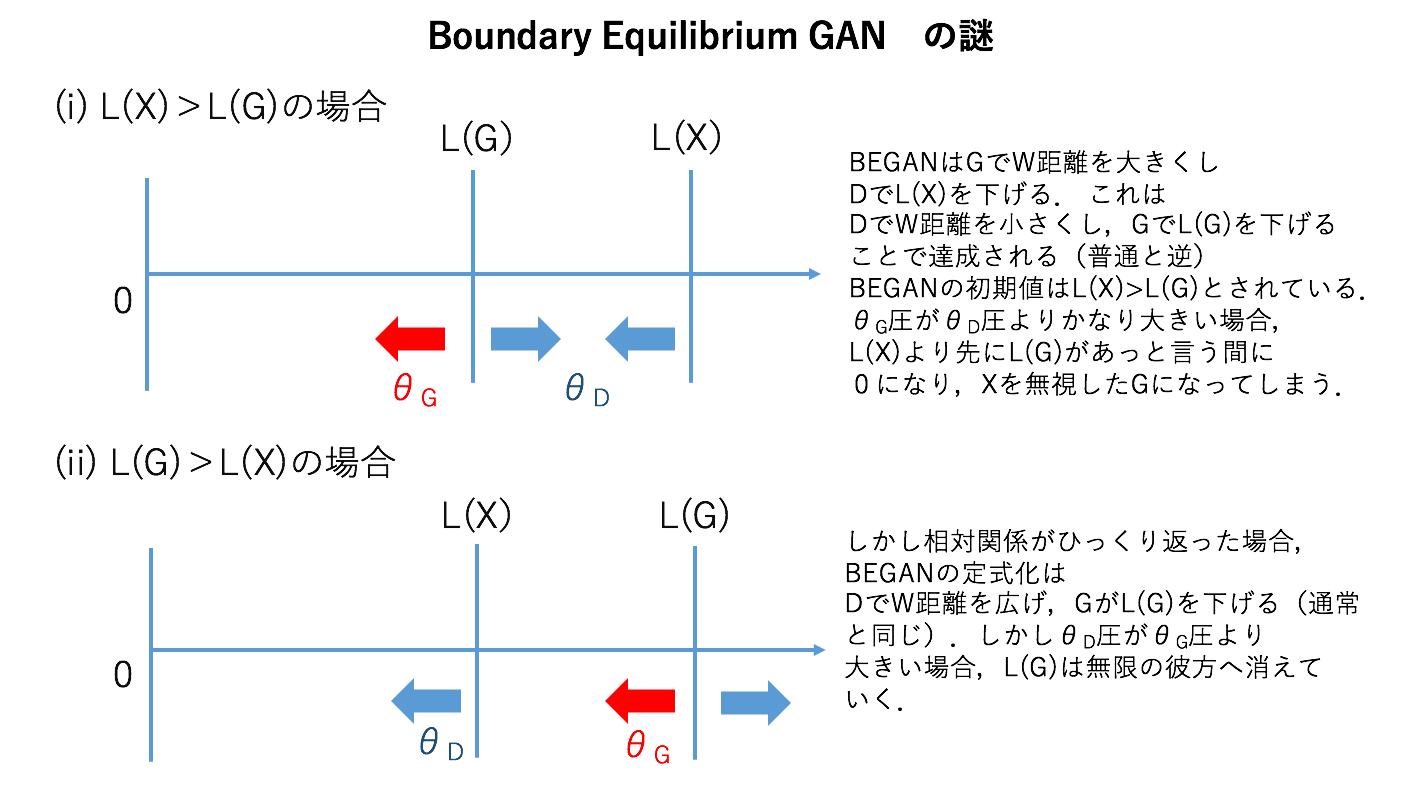
G : がより大きい時は、今まで通りみたいですね。
M : でも、学習初期ではって書いてたね。
In early training stages, G tends to generate easy-to-reconstruct data for the auto-encoder since generated data is close to 0 and the real data distribution has not been learned accurately yet. This yields to L(x) > L(G(z))
(i)の場合は、 があっという間に0になってしまわないか?ここすごい気持ち悪い。guguchiが前の記事で言ってたmin-maxとmax-minの問題に戻ってくる気がする。というのも、最悪のdiscrimiantorに耐えるようなgeneratorを作るのがGANの正当性だった。この正当性の観点から言うと、についてくるようにを誘導するのが目指すべき目的だ。でも、定式化はが0に近づいていくから初めてが0に近づける。これって本末転倒じゃん。変なことが起きそう。
G : じゃあがより先に0にならないためには、の最適化のスピードがの最適化のスピードが速くないといけない。するとがを追い越して、(ii)になる。この場合は、の最適化のスピードがの最適化のスピードが速いと、が無限の彼方に吹っ飛んでしまう。だから、(ii)では、の最適化のスピードがの最適化のスピードが速くないといけない。つまり、(i)から(ii)へ移った時、の最適化のスピードとの最適化のスピードの大小関係が入れ替わって欲しい感じになってますね。
M : でも、3.3 Equilibriumを見るに、その追い越しが起きないように制御工学を使って
になるように調整してるよね。しかもこれ、が先に0にならないようにする調整も担ってるっぽいね。
G : それって、この式のことですか?
この式は、追い越しをなくす効果はなくないですか?
M : あぁそうだね。 とすると、が大きい時は、を小さすぎる。だからを大きくしてについて来させる。がマイナスになったり、0に近くなってWasserstein距離の計算で使われた’ratio’が不安定になりそうになったら、を小さくしてる。
G : 結局これって、入れ替わりが頻繁に起こるから、学習はめっちゃ不安定になりそうですね。再現実験してる記事何個か見ましたけど、学習めっちゃ大変そうでした。これのせいなんですかね?(musyokuさんの記事 , underfittingさんの記事 , rcallandさんのgithub)
D : との軌道を見てみたいね。上手くいかない場合と上手くいく場合どんな違いがあるんだろう?
G : 乞うご期待!!!(GPUがなくて死ぬ音)
M : Give me Grants…